Zezo copy
2024-02-27
tại sao kafka lưu dữ liệu trên disk mà vẫn nhanh?
Why kafka fast
Các công nghệ thông thường:
- batch, compression: gom nhóm và nén trước khi gửi.
- horizontally scaling: chia nhiều partition trong 1 topic
Các công nghệ riêng:
- sequential I/O: chỉ append vào, lưu lại offset để đọc và đọc tuần tự. khắc phục điểm yếu về disk chậm hơn ram. bù lại được lợi ích kinh tế khi k cần sử dụng ram.
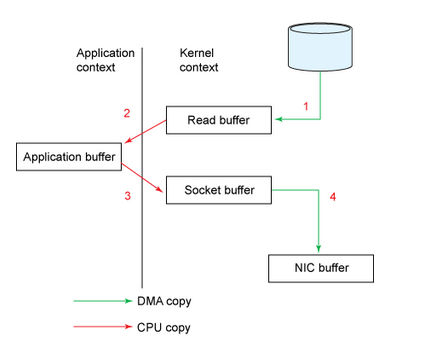
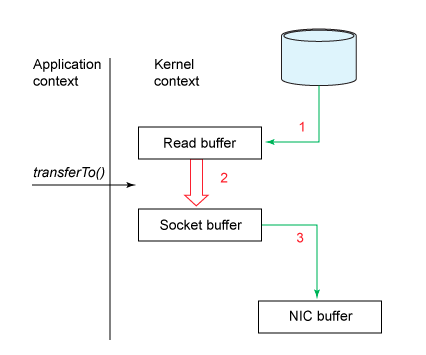
- zezo copy: đọc trực tiếp từ disk ghi lên buffer trả về cho client. không thông qua application bufer như thông thường.
Zezo copy
Cơ chế đọc ghi thông thường. cần chuyển context từ app context sang kernel context (và ngược lại, tổng cộng 4 lần ).
code
FileInputStream in = new FileInputStream("in.txt");
FileOutputStream out = new FileOutputStream("out.txt");
int c;
while ((c = in.read()) != -1) {
out.write(c);
}
in.close();
out.close();
Latency cơ bản
L1 cache reference 0.5 ns
Branch mispredict 5 ns
L2 cache reference 7 ns 14x L1 cache
Mutex lock/unlock 25 ns
Main memory reference 100 ns 20x L2 cache, 200x L1 cache
Compress 1K bytes with Zippy 3,000 ns 3 us
Send 1K bytes over 1 Gbps network 10,000 ns 10 us
Read 4K randomly from SSD* 150,000 ns 150 us ~1GB/sec SSD
Read 1 MB sequentially from memory 250,000 ns 250 us
Round trip within same datacenter 500,000 ns 500 us
Read 1 MB sequentially from SSD* 1,000,000 ns 1,000 us 1 ms ~1GB/sec SSD, 4X memory
Disk seek 10,000,000 ns 10,000 us 10 ms 20x datacenter roundtrip
Read 1 MB sequentially from disk 20,000,000 ns 20,000 us 20 ms 80x memory, 20X SSD
Send packet CA->Netherlands->CA 150,000,000 ns 150,000 us 150 ms
Giảm số lần copy dữ liệu và số lần context switch.
code
FileChannel inChannel = new FileInputStream("in.txt").getChannel();
FileChannel outChannel = new FileOutputStream("out.txt").getChannel();
inChannel.transferTo(0, inChannel.size(), outChannel);
inChannel.close();
outChannel.close();