Spark Streaming vs Structured Streaming
2024-02-27
đã sinh ra Spark Streaming lại sinh ra Structured Streaming
So sánh
| Spark Streaming | Structured Streaming | |
|---|---|---|
| import | là 1 package riêng spark-streaming_2.12 + spark-streaming-kafka-0-10_2.12 | có sẵn trong spark-sql_2.13 từ 2.x |
| api | DStream API from Spark RDDs | Dataframe, Dataset APIs -> dùng được sql. Dataframe thì kiểu jh cũng optimize hơn rdd của bên trái |
| cơ chế | micro batch theo duration | k có khái niệm batch, các data mới đến được append vào một unbounded result table. |
| data late | chỉ xử lí theo thời gian mà spark nhận được data đó. với các dữ liệu đến trễ do latency thì coi như mất với batch đó | có thể xử lí dữ liệu event-time (các dữ liệu tới trễ). đây cũng là 1 trong những feature chính của structure streaming |
| End to end guarantees | cả 2 đều có cơ chế checkpoint | có cơ chế restricted sinks : hỗ trợ exactly once tốt hơn |
| sink | không hạn chế bao nhiêu sink. foreachRDD | foreachBatch |
*sink: kết quả của stream operator được gửi tới một nơi gọi là sink (sink - destination of a streaming operation). ví dụ: storage, print console. đặc điểm của sink là tính imdempotent
Code
Spark Streaming
import org.apache.spark.*;
import org.apache.spark.api.java.function.*;
import org.apache.spark.streaming.*;
import org.apache.spark.streaming.api.java.*;
import scala.Tuple2;
// Create a local StreamingContext with two working thread and batch interval of 1 second
SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount");
JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(1));
// Create a DStream that will connect to hostname:port, like localhost:9999
JavaReceiverInputDStream<String> lines = jssc.socketTextStream("localhost", 9999);
// Split each line into words
JavaDStream<String> words = lines.flatMap(x -> Arrays.asList(x.split(" ")).iterator());
// Count each word in each batch
JavaPairDStream<String, Integer> pairs = words.mapToPair(s -> new Tuple2<>(s, 1));
JavaPairDStream<String, Integer> wordCounts = pairs.reduceByKey((i1, i2) -> i1 + i2);
// Print the first ten elements of each RDD generated in this DStream to the console
wordCounts.print();
jssc.start(); // Start the computation
jssc.awaitTermination(); // Wait for the computation to terminate
hello world
(hello,1)
(world,1)
Structure Streaming
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.sql.*;
import org.apache.spark.sql.streaming.StreamingQuery;
import java.util.Arrays;
import java.util.Iterator;
SparkSession spark = SparkSession
.builder()
.appName("JavaStructuredNetworkWordCount")
.getOrCreate();
// Create DataFrame representing the stream of input lines from connection to localhost:9999
Dataset<Row> lines = spark
.readStream()
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load();
// Split the lines into words
Dataset<String> words = lines
.as(Encoders.STRING())
.flatMap((FlatMapFunction<String, String>) x -> Arrays.asList(x.split(" ")).iterator(), Encoders.STRING());
// Generate running word count
Dataset<Row> wordCounts = words.groupBy("value").count();
// Start running the query that prints the running counts to the console
StreamingQuery query = wordCounts.writeStream()
.outputMode("complete")
.format("console")
.start();
query.awaitTermination();
apache spark
apache hadoop
-------------------------------------------
Batch: 0
-------------------------------------------
+------+-----+
| value|count|
+------+-----+
|apache| 1|
| spark| 1|
+------+-----+
-------------------------------------------
Batch: 1
-------------------------------------------
+------+-----+
| value|count|
+------+-----+
|apache| 2|
| spark| 1|
|hadoop| 1|
+------+-----+
Structure streaming trigger
Spark streaming: fix duration
Structure streaming: Khoảng thời gian mà nó processing. mặc định là cứ xong micro-batch trước là thực hiện.
import org.apache.spark.sql.streaming.Trigger
// Default trigger (runs micro-batch as soon as it can)
df.writeStream
.format("console")
.start();
// ProcessingTime trigger with two-seconds micro-batch interval
df.writeStream
.format("console")
.trigger(Trigger.ProcessingTime("2 seconds"))
.start();
...
Structure streaming append row
Spark streaming: chia theo batch của input và sử lí như spark bình thường (convert streaming về batch)
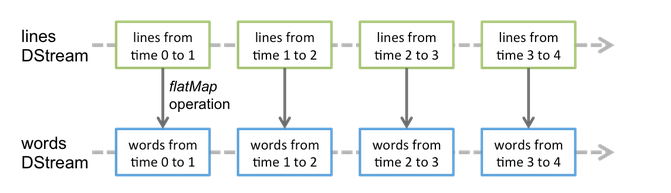
Structure streaming: append vào 1 table
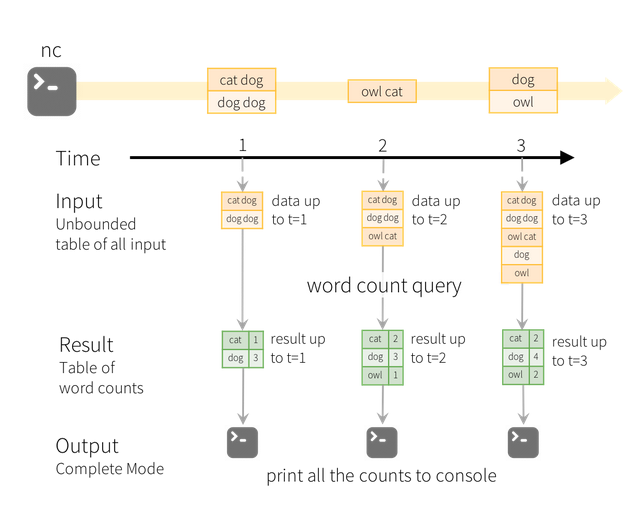
Structure streaming window late
Spark streaming: window length(3), sliding interval(2)

Structure streaming: late được cập nhật lại
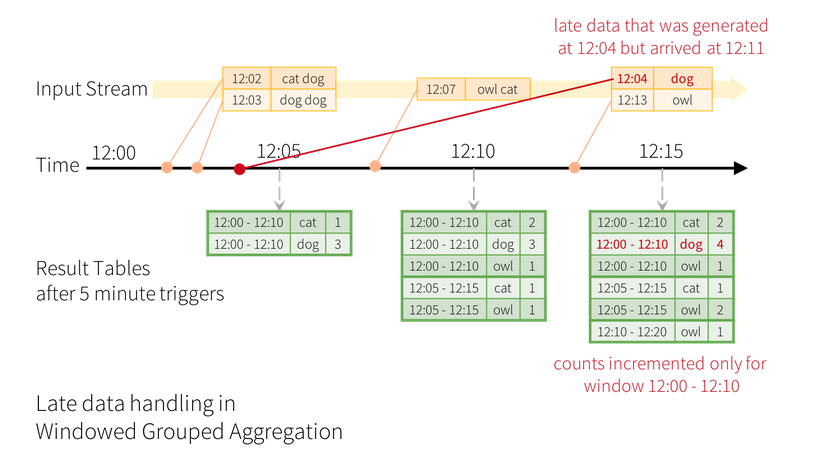
Vấn đề: data quá trễ (tính đến đơn vị ngày) thì có thể dữ liệu đã k còn trên ram -> watermarking in spark 2.1.